
阿里巴巴通义千问团队发布了Qwen2系列开源模型,该系列模型包括5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B
一、下载GGUF文件
gguf就是一种二进制格式文件的规范,原始的大模型预训练结果经过转换后变成GGUF格式可以更快地被载入使用,也会消耗更低的资源。原因在于GGUF采用了多种技术来保存大模型预训练结果,包括采用紧凑的二进制编码格式、优化的数据结构、内存映射等。
下载Qwen2-7B模型文件
通过访问qwen开发文档中的效率评估(https://qwen.readthedocs.io/zh-cn/latest/benchmark/speed_benchmark.html),选择适合自己的模型
根据自身情况,选择适当模型(https://modelscope.cn/models/qwen/Qwen2-7B-Instruct-GGUF/files)。
![image.png]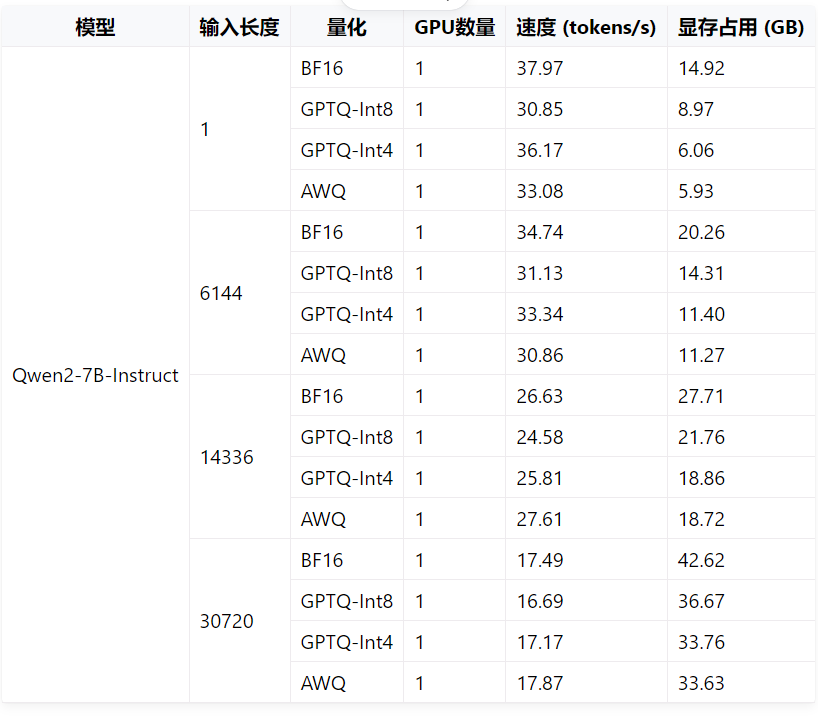 另发现,该网站下载大文件对网速及稳定性有极大要求,不能续传和多线程下载。
另发现,该网站下载大文件对网速及稳定性有极大要求,不能续传和多线程下载。
笔者选了qwen2-7b-instruct-q4_k_m.gguf
二、安装ollama
Ollama(https://ollama.com/download)是一个为大型语言模型 (LLMs) 提供本地推理 (local inference) 的应用程序。它允许用户在本地运行和推理大型语言模型,而无需依赖云服务。这意味着你可以在本地计算机上运行类似 ChatGPT 之类的模型,并且完全控制数据和隐私。Ollama 提供了一种方便的方式来下载和运行不同的语言模型,且其使用界面友好,适合开发者和对 AI 模型感兴趣的个人用户。
Ollama的安装与其他软件安装无异,正常安装即可
Ollama的路径情况如下:
windows 的安装默认不支持修改程序安装目录,
默认安装后的目录:C:\Users\username\AppData\Local\Programs\Ollama
默认安装的模型目录:C:\Users\username\ .ollama
默认的配置文件目录:C:\Users\username\AppData\Local\Ollama
如果需要更改模型路径,通过修改系统环境变量,如下: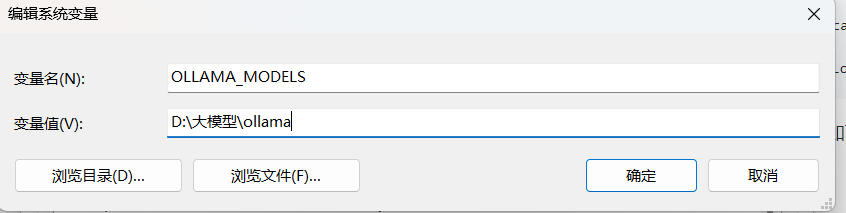
三、安装node.js
安装node.js(https://nodejs.org/en/download/prebuilt-installer)也是和其他软件一样,正常安装即可
四、python安装依赖包
pip install llama-cpp-python
pip install openai
pip install uvicorn
pip install starlette
pip install fastapi
pip install sse_starlette
pip install starlette_context
pip install pydantic_settings如果安装llama-cpp-python报错,是由于该依赖包在安装的过程中需要打包,系统缺少环境。因此,需要下载VisualStudio 2022 + C++ building tool(https://visualstudio.microsoft.com/zh-hans/vs/),安装c++桌面开发,随后重新运行即可
五、运行模型
在gguf根目录下,创建一个文件名为Modelfile的文件,内容如下:
FROM ./qwen2-7b-instruct-q4_k_m.gguf通过dos命令运行
//Qwen2-7B为文件名
ollama create Qwen2-7B -f ./Modelfile
Ollama常见命令如下
Ollama list //本地模型列表
Ollama rm Qwen2-7B //删除本地模型
Ollama create Qwen2-7B -f ./Modelfile //创建模型即可查看本地模型文件列表
运行Qwen2-7B模型
ollama run Qwen2-7B六、可视化对话
Ollama - UI下载(https://github.com/ollama-webui/ollama-webui-lite),随后进入到该UI源码路径下node.js换源
npm config set registry http://mirrors.cloud.tencent.com/npm/安装依赖包
npm install运行
npm run dev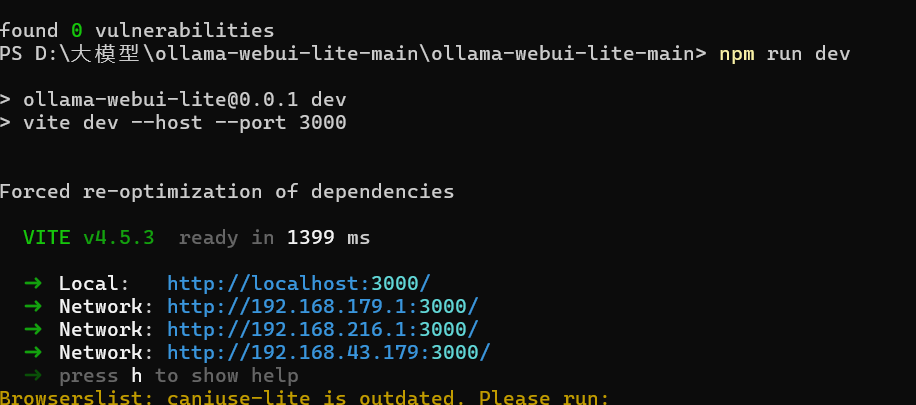
访问3000端口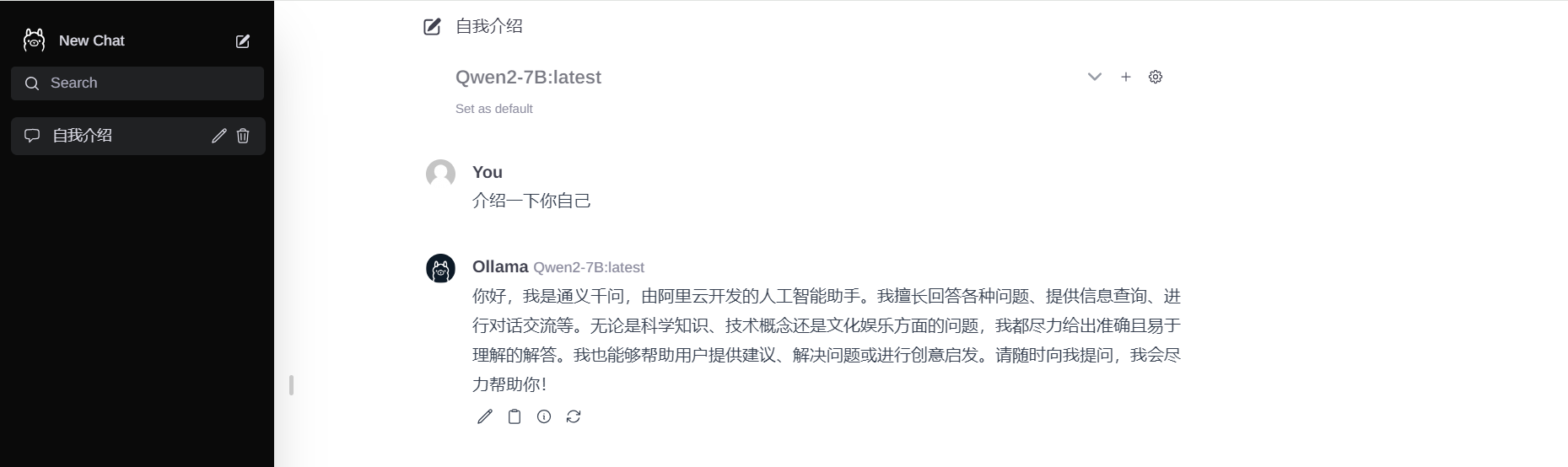
本文作者:硝基苯
本文链接:https://www.c6sec.com/index.php/archives/963/
最后修改时间:2024-08-24 21:24:04
本站未注明转载的文章均为原创,并采用 CC BY-NC-SA 4.0 授权协议,转载请注明来源,谢谢!